تاثیر LLMs.txt بر پاسخهای مدلهای هوش مصنوعی
- mehdisabet
- سئو

در چند ماه اخیر فایل llms.txt بهعنوان یکی از روشهای جدید برای مدیریت نحوه دسترسی مدلهای هوش مصنوعی به محتوای سایت مطرح شده است. بسیاری از مدیران وبسایتها تصور میکنند این فایل میتواند نقشی مشابه robots.txt اما مخصوص مدلهای زبانی ایفا کند و شاید باعث افزایش دیدهشدن سایت در خروجیهای هوش مصنوعی شود. با این حال، تحلیل تازهای که توسط SE Ranking بر اساس دادههای حدود ۳۰۰ هزار دامنه انجام شده، نشان میدهد این انتظار حداقل در مقطع فعلی واقعیت ندارد.
بیشتر بخوانید: چگونه سایت خودمون رو برای ChatGPT بهینهسازی کنیم؟
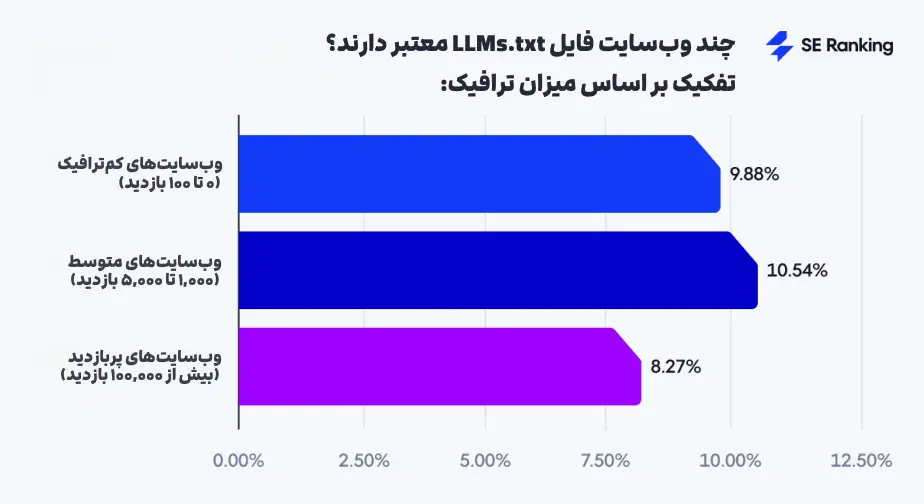
استفاده از llms.txt هنوز بسیار محدود است
SE Ranking در خزش خود تنها روی ۱۰ درصد دامنهها فایل llms.txt را پیدا کرده است؛ یعنی تقریباً از هر ۱۰ سایت، تنها یک سایت به سراغ استفاده از این فایل رفته است. این آمار پایین نشان میدهد هنوز توافق یا استاندارد قطعی درباره ضرورت استفاده از آن شکل نگرفته و استفاده از آن بیشتر جنبه آزمایشی دارد.
نکته جالب اینکه استفاده از این فایل تنها محدود به برندهای بزرگ یا سایتهای پرقدرت نیست. در واقع، بین سایتهای پربازدید، دامنههایی که از llms.txt استفاده کردهاند حتی کمتر از سایتهای متوسط بودهاند. این موضوع نشان میدهد که حتی بازیگران اصلی وب نیز هنوز نسبت به مزایای این فایل مطمئن نیستند.

llms.txt هیچ رابطهای با میزان استناد مدلهای زبانی ندارد
SE Ranking در خزش خود تنها روی ۱۰ درصد دامنهها فایل llms.txt را پیدا کرده است؛ یعنی تقریباً از هر ۱۰ سایت، تنها یک سایت به سراغ استفاده از این فایل رفته است. این آمار پایین نشان میدهد هنوز توافق یا استاندارد قطعی درباره ضرورت استفاده از آن شکل نگرفته و استفاده از آن بیشتر جنبه آزمایشی دارد.
نکته جالب اینکه استفاده از این فایل تنها محدود به برندهای بزرگ یا سایتهای پرقدرت نیست. در واقع، بین سایتهای پربازدید، دامنههایی که از llms.txt استفاده کردهاند حتی کمتر از سایتهای متوسط بودهاند. این موضوع نشان میدهد که حتی بازیگران اصلی وب نیز هنوز نسبت به مزایای این فایل مطمئن نیستند.
به بیان ساده:
فعلاً داشتن llms.txt هیچ تأثیری بر دیدهشدن یا استناد محتوا در LLMها ندارد.
نتایج تحقیق با راهنمایی پلتفرمها هم هماهنگ است
این یافتهها با آنچه پلتفرمهای اصلی اعلام کردهاند نیز سازگار است. گوگل در هیچیک از مستندات مربوط به AI Overviews یا AI Mode اشاره نکرده که llms.txt یک سیگنال برای رتبهبندی یا استناد محسوب میشود. در بیانیههای گوگل تأکید شده که سیستمهای جستجوی هوش مصنوعی همچنان بر پایه سیگنالهای سنتی سرچ کار میکنند.
OpenAI نیز در مستندات خزندههای خود بیشتر روی robots.txt تمرکز دارد و تنها پیشنهاد میکند برای کمک به کشف محتوا توسط OAI-SearchBot، دسترسی آن در robots.txt باز باشد. هیچ اشارهای هم نشده که llms.txt نقشی در رتبهبندی یا انتخاب منابع دارد.
SE Ranking همچنین اشاره میکند که در برخی لاگها دیده شده GPTBot گاهی llms.txt را درخواست میکند، اما این اتفاق نادر است و هیچ نشانهای وجود ندارد که این رفتار روی میزان استناد تأثیر بگذارد.
این نتایج چه معنایی برای مدیران سایت دارد؟
پیادهسازی llms.txt کار پیچیدهای نیست و از نظر فنی تقریباً هیچ ریسکی ندارد. بنابراین اگر کسی میخواهد سایت را برای آینده آماده نگه دارد، استفاده از آن منطقی است. اما اگر انتظار دارید در کوتاهمدت باعث افزایش دیدهشدن یا بهبود در خروجیهای هوش مصنوعی شود، دادهها نشان میدهد چنین انتظاری واقعبینانه نیست.
به عبارت دیگر، llms.txt در حال حاضر بیشتر یک ابزار آزمایشی است؛ چیزی که میتوان تست کرد اما نمیتوان آن را بهعنوان یک راهحل تثبیتشده برای بهبود «AI Visibility» معرفی کرد.
جمعبندی
اطلاعات حاصل از بررسی گسترده SE Ranking نشان میدهد که فایل llms.txt هنوز هیچ اثر مستقیم و قابلاندازهگیری بر استنادهای مدلهای هوش مصنوعی ندارد. استفاده از آن کم است، میان سایتهای مختلف پراکندگی خاصی ندارد و هیچ ارتباطی با افزایش دیدهشدن در LLMها مشاهده نمیشود.
تا زمانی که پلتفرمها نقش دقیق این فایل را شفافتر نکنند، بهتر است آن را یک اقدام کمهزینه برای آینده بدانیم، نه ابزاری برای کسب نتایج کوتاهمدت.


